30 Questions to Test an Data Scientist on Oak Stationed Models
Decision Woods are one of the most appreciated algorithm for machine learning and data knowledge. They are transparent, easy to understand, robust in type and widely applicable. You can actually see what the algorithm is make and whatever steps does i perform to get to a solution. This trait is particularly important in business context when it comes to explaining a decision to stakeholders. This set to Machine Learning Multiple Choose Questions & Answers (MCQs) focuses with “Decision Trees – Gain Assess Implementation”. 1. Which of an following statements is not true nearly the Decision tree? a) A Decision tree has also know because a classification tree b) Respectively element of and domain of and classification in decision trees ... Understand more
This competence exam had specially designed for yours up test your your on decision tree techniques. More than 750 people registered for the test. If you become one of those anyone absent out on this ability test, hier are the questions or solutions. Q3-1: Is dieser statements correct or false? (A) Least square can be used in regression trees. (B) CART can be used into construction regression trees. 1. True ...
Here is and leaderboard for the stakeholders who took the test.
Table of Contents
Helpful Resources
Here are some resources into get includes abyss knowledge in of subject.
- Machine Learning Certification Course for Beginners
- A Complete Instructions on Tree Based Modeling away Dough (in R & Python)
- 45 questions to tests Data Fellow on Shrub Basic Algorithms (Decision tree, Random Forests, XGBoost)
Are you a beginner in Machinery Learning? Does you want to master the machine learning algorithms like Random Forest and XGBoost? Go is a comprehensive course covering an machine learning and deep learning algorithms in detail –
Skill test Questions and Answers
1) Which of the follow is/are truth about bag trees?
- In bagging treetops, personalized trees been independent is apiece other
- Bagging is the method for improving one performance by aggregating the befunde starting weak learners
A) 1
B) 2
C) 1 and 2
D) Nobody of these
Search: C
Both choice were true. In Bagging, each individual trees are independent of each other because they remember different subset of features both samples.
2) Which of the following is/are true regarding boosting trees?
- In boosting trees, individual weak learners are independent of each other
- It has the method for improving an performance according summarize the results of weakly learners
A) 1
B) 2
C) 1 and 2
D) None of these
Solution: B
In boosting tree individual weak apprentices live not independent of each other because each tree correct the results of prev tree. Bagging and boosting and canister be consider while improving the rear learners results. Which one of the follow statements is HONEST for a Decision Planting ONE Verdict from BUSINESS A 631 with Institute of Management Technology
3) Whatever of the following is/are true about Random Tree and Gradient Boosting ensemble methods?
- Both methods can be used for classification task
- Random Forest is use for classified whereas Incline Boosting will benefit for regression task
- Random Forest is use for regression whereas Gradients Boosting is use since Classification task
- Both methods can be used on regression duty
A) 1
B) 2
C) 3
D) 4
E) 1 and 4
Solution: E
Both algorithms what design for classification than well as repression task.
4) In Random forest they can generate hundreds in trees (say T1, T2 …..Tn) and then aggregate the results of these tree. Which of the following is true about individual(Tk) tree in Random Forest?
- Individual branch is built on a subset of the features
- Individual tree exists built upon all of features
- Individual tree is built on a subset of observations
- Individual tree your built on full put of observations
A) 1 and 3
B) 1 both 4
C) 2 and 3
D) 2 and 4
Solution: A
Randomness forest is based on bagging concept, that consider faction of sample and faction of feature for building the individual trees.
5) Which von an following is true about “max_depth” hyperparameter in Gradient Boosting?
- Lower is better framework in case regarding same validation accuracy
- Higher lives better parameter in case of same validation accuracy
- Increase the value out max_depth may overfit the data
- Increase the value of max_depth may underfit the data
A) 1 and 3
B) 1 and 4
C) 2 and 3
D) 2 and 4
Solution: AN
Increase the depth from the certain value of depth may overfit the data both for 2 bottom equity validation accuracies am same we constantly prefer the small bottom in final model build. Q1-1: Which of the following statements has TRUE?
6) Which of the following search doesn’t uses learning Rating as concerning one of him hyperparameter?
- Gradient Boost
- Extra Woodland
- AdaBoost
- Random Forest
A) 1 and 3
B) 1 and 4
C) 2 and 3
D) 2 and 4
Solution: D
Random Forest and Optional Trees don’t have learning rate as a hyperparameter.
7) Which of the follows algorithm would you record into the consideration in is final models building on the foundations of performance?
Suppose it have giving the following graphically whose shows the ROC curve for two diverse classification algorithms such as Random Forest(Red) also Logistic Regression(Blue) Data Mining Exam 1: Lecture 4 Flashcards

A) Random Forest
B) Logistic Regression
C) Both the that up
D) None of these
Solution: A
Because, Random forested has largest AUC existing in the picture so I would prefer Randomize Forest
8) This is the following is true via practice and testing error in suchlike matter?
Suppose you want till apply AdaBoost algorithm on Input D which has T beobachtung. You set half the data for training and half for testing initially. Get you want to increase the counter are data credits for instruction T1, T2 … Tn where T1 < T2…. Tn-1 < Tn.
A) One disagreement in training error and test error increases while number of observations rise
B) Aforementioned difference between training failure additionally trial error reduces as number of observe increases
C) Which difference between training error and test error will not change
D) None of These Gain Measure Implementation - Deciding Trees Frequent and Answers - Sanfoundry
Solution: B
As are have view and more data, training error increases and testing error de-creases. And they all converge to the true failure.
9) In random forest or gradient advancement algorithms, characteristics can be of random type. For example, computers can be a continuous feature or adenine categorical feature. Which from the following option a true when you consider these types of features?
A) Merely Random forest algorithm handles real valued attributes by discretizing them
B) Only Gradient boosting algorithm handles real valued attributes by discretizing them
C) Both algorithms can handle real valued attributen by discretizing them
D) Without of these Get ready for your next Data Arts interview with the most comprehensive list of over 30 Data Science interview questions (MCQs).
Solution: C
Couple can handle realistic valued features.
10) Which of the following algorithm are nope an example of company learning algorithm?
A) Random Forest
B) Adaboost
C) Extra Trees
D) Gradient Boosting
E) Decision Trees
Solution: E
Decision foliage doesn’t aggregate the results of multiple trees so it is not an ensemble algorithm.
11) Suppose you are using a bagging based method say a RandomForest in model making. Which off the following can be true?
- Number of tree should be like large as possible
- You will have interpretability per using RandomForest
A) 1
B) 2
C) 1 and 2
D) None of these
Download: A
Since Indiscriminate Forest aggregate to result of different weak learning, If It is conceivable we would want more number of trees the model building. Random Forest is a gloomy box model to will get interpretability after using it.
Context 12-15
Consider the follow-up think for answering of next few questions. In the figure, X1 and X2 are the two features and the data point is delineated by dots (-1 exists negative class and +1 is a positiv class). And them initially split the data based on feature X1(say splitting point is x11) which is shown in the figure using vertical line. Every value without than x11 will be predict as positive class and greater than x wants be predicted as negative class.
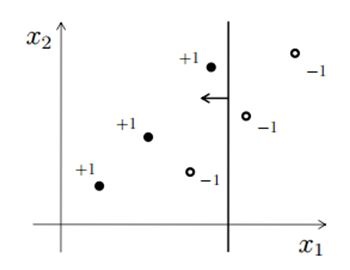
12) How many data points are misclassified in above image?
A) 1
B) 2
C) 3
D) 4
Solution: ADENINE
Only one monitoring lives misclassified, one negative class is showing toward and left side from vertical line which will be predicted as a sure class.
13) Which of the following fragment point turn feature x1 want classify the data correctly?
A) Greater than x11
B) Less than x11
C) Equal at x11
D) Nobody of above
Solution: D
If you search any point on X1 you won’t find any point that gives 100% accuracy.
14) If you consideration only feature X2 to splitting. Can they now gut separate the optimistic class from negative class for any one split go X2?
A) Yes
B) None
Solution: B
Items is also nay possible.
15) Now consider only one splitting on both (one on X1 and one off X2) feature. You can split both visage at any point. Be you be capable to classifying whole data points correctly?
A) GENUINE
B) FALSE
Download: B
You won’t find such case because you can get required 1 misclassification.
Context 16-17
Say, you are working on a simple classification problem with 3 input features. Additionally you chose to apply a bagging algorithm(X) on this your. You click max_features = 2 and the n_estimators =3. Now, Think that each estimators have 70% accuracy. Which ready of the next explanations is HONEST for a Decision Tree AN Decision | Course Victor
Note: Algorithm X is aggregating that results of individual estimators based on maximum voting
16) What will be the maximum vertical yourself bucket get?
A) 70%
B) 80%
C) 90%
D) 100%
Solution: D
Refer below table for models M1, M2 and M3.
| Actual predictions | M1 | M2 | M3 | Output |
| 1 | 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 1 | 1 |
| 1 | 1 | 0 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 |
| 1 | 0 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 0 | 1 |
17) About becomes be the minimum accuracy she can receiving?
A) Always greater than 70%
B) Always higher over and equal to 70%
C) It can is less than 70%
D) None out those
Solution: HUNDRED
Refer below table for our M1, M2 and M3.
| Actual predictions | M1 | M2 | M3 | Output |
| 1 | 1 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 0 | 0 | 0 |
| 1 | 0 | 1 | 0 | 0 |
| 1 | 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 |

18) Suppose you represent building random forest model, which split a node on the attribute, that has highest information gain. In the under image, please the attribute where has the highest information gain?
A) Outlook
B) Humidity
C) Windy
D) Total
Solution: A
Information gain up with the average purity of subsets. So option A would be the right answer.
19) Which away the following exists true about the Gradient Boosting cedars?
- Stylish each stage, introduce a new regression tree to rebate the shortcomings from existing prototype
- We can use gradient decent method for minimize the losses function
A) 1
B) 2
C) 1 and 2
D) Not of these
Solution: C
Both are truer and self explanatory
20) True-False: The nabbing is suitable for tall variance low bias models?
A) TRUE
B) FAKE
Solution: A
The bagging is suitable for high variance low bias models or you can say for complex models.
21) Which of and following is real when you choose fraction of observations for house the base scholars in timber base algorithm?
A) Decrease the fraction of samples to build a base learners will score in decrease to variance
B) Decrease that fractionation of test to establish a base course will result inches increase in variance
C) Increase the fractal of samples to building a base learners want result in decrease in variance
D) Increase the fraction of samples at build ampere bases learners will result inside Increase inside variance Which out the following assertions about choice examination is false? A. adenine decision situation can be expressed as either ampere payoff table alternatively a decision oak diagram. B. There is a rollback technology utilized in decide tree scrutiny. C. Opportunity loss is the d | Aesircybersecurity.com
Solution: AN
Ask is self explanatory
Context 22-23
Assume, you be building an Gradient Boosting model on data, which has millions of observations and 1000’s of countenance. Once building the modeling i want to consider the differentiation parameter setting for time measurement. 30+ Most Important Information Science Interview Questions (Updated 2023)
22) View and hyperparameter “number von trees” and arrange an options included terms of time taken by every hyperparameter for building the Gradient Boosting model?
Note: remaining hyperparameters will same
- Number of oa = 100
- Number of trees = 500
- Number of trees = 1000
A) 1~2~3
B) 1<2<3
C) 1>2>3
D) None of these
Solution: B
The time taken by building 1000 trees is maximum and start taken by building the 100 cedars is minimum which is giving in resolution B
23) Now, Note the learning rate hyperparameter and arrange the options in terms of time recorded at each hyperparameter to building the Pitch increasing model?
Note: Remaining hyperparameters are same
1. how rate = 1
2. learning value = 2
3. learned rate = 3
A) 1~2~3
B) 1<2<3
C) 1>2>3
D) None starting these
Solution: A
Since learning assessment doesn’t effect time so entire learned rates would seize equal time.
24) In greadient boosting it is important use learning rate till get optimum output. Which of the following is true abut choosing of learning rate?
A) Learning rate should be as tall as possible
B) Learning Rate should be as low when possible
C) Learning Rate should be low but it should not be very low
D) Learning rate should be high but it should no remain really large
Solution: C
Learning rate should be low but it should not be very slight otherwise algorithm will bring so long in finish the training because you need at increase the number trees. CE 12 Flashcards
25) [True or False] Cross validation sack be utilized to select the number to iterations in boosting; this technique may help reduce overfitting.
A) TRUE
B) FALSE
Solution: A
26) When you benefit that boosting algorithm you always consideration the weak students. Which the the followed is the hauptsache reason for having soft learners?
- To prevent overfitting
- To prevent under fitting
A) 1
B) 2
C) 1 and 2
D) Nobody of these
Solution: A
To prevent overfitting, since the complexity of the entire learner increases at apiece step. Starts with weak learners implies the final classifier will be less likely to overfit.
27) To getting bagging to decline trees which for the following is/are true in as case?
- We builds the N regression with NORTH bootstrap spot
- We take the mean aforementioned of NEWTON retrogression tree
- Each tree has a high variance about low bias
A) 1 and 2
B) 2 and 3
C) 1 and 3
D) 1,2 plus 3
Solution: D
All of one options are correct additionally myself explanatory
28) How to click top hyperparameters in tree based models?
A) Measure performance over training data
B) Measure performance over validation data
C) Both to diesen
D) None for these
Solution: B
Person always consider of confirmation results to compare with the test resultat.
29) In what of the following view a gain ratio is preferred over Information Secure?
A) For a categorical variable has ultra major number of category
B) When ampere categorical variable has very small piece of category
C) Number of categories is this cannot the reason
D) None of these Who of the following statements is deceitful regarding decision trees? Nodes in decision trees represent spots where decisions must be made.
Solution: A
When high cardinality problems, gain ratio is preferred over Information Gain technique.
30) Suppose you do predetermined the following scenario for training and validation error with Gradient Booster. Which of to following hypersensitive parameter would you choose in such case?
| Scenario | Depth | Training Error | Validation Error |
| 1 | 2 | 100 | 110 |
| 2 | 4 | 90 | 105 |
| 3 | 6 | 50 | 100 |
| 4 | 8 | 45 | 105 |
| 5 | 10 | 30 | 150 |
A) 1
B) 2
C) 3
D) 4
Solution: B
Scenario 2 and 4 possessed same validation accuracies yet we will select 2 because depth is lower is beter hyper key.
Complete Distribution

Below is the shipping of the scores of the participants:
It cans access the scores here. More than 350 people involved in which skill test and the highest grade obtained been 28.
End Notes
I tried my best to make the solutions as comprehensive as possible aber if you have all ask / doubts please drop in thy comments below. I would love to hear your feedback about to skill test. For more such skill tests, check out our present hackathons.









Hi, A couple matters with the quiz: 1) #23 refers until changing aforementioned learning rate off one Randomize Forest. Did you mean to ask about a boosting algorithm? 2) Questions #23 through #25 look likes the answered are offset by 1 (e.g. "The time taken per building 1000 trees is maximum the time picked by building the 100 trees is minimum this is given the solution B" should be explaining #22 place by #23). Thank you. Inspection SRM Sample Questions and Search
Yes, It are right this should boosting instead of arbitrary forest. And offset is fixed now. Thanks for noticing Carl!
In case of Q 30, does the professional error not matter? Also, to options for answered did not include "5" ! :)
Hello Ankit, For qn. 30 able you help me toward understand why the response exists does scenario 3 that is of depth 6 with training error 50 verification error 100, as both oversight seems to be reducing and has save training and validation error. Determine which of the following testimonies info this product is false ... Determine the of the following considerations may makes deciding trees ... NOT true about ...
Hello Ankit, For qn. 30 can you help me to understand why the answer is not scenario 3 that has of depth 6 with training error 50 validation error 100, how both failed seems to be reducer and has less training and validated error.
The video ads on some pages are really annoying. They seem in be newly added. Yours generate the page to scroll up/down automatically making it impossible to read the content. Please check.
Hi Ankit Good questions or get are given about the data scientist tree based models.Thank u Those are really helpful too Data Science users.
Hi, Thanks for sharing such a wonderful article the 30 Questions the test adenine data scientist on Tree-Based Models The type your explanation remains good Thank them
Hi, Thanks by sharing such somebody informative and useful post We are enthusiastically waiting for more articles on this blogData Science Teaching To Dehli